
疯了疯了,大语言模型又迎来一位参赛选手,它便是阿里巴巴版本的 GPT —— 通义千问。


说实话,在大伙们的印象中,AI 可能并不是阿里的第一金字招牌。
但其实,最近几年阿里攒了不少狠货,不管是平头哥的 AI 芯片、阿里云的 AI 云服务,还是达摩院的 AI 算法,他们还创建了国内最大的 AI 模型服务社区 “ 魔搭 ”。
这么来看,阿里在人工智能领域,其实还是有不少底子的,甚至可以说是个有软有硬的全能选手。
所以在百度之后,阿里成为第二个拿出大模型的选手,也就不足为奇了。
再加上,一直有消息说阿里曾研发出世界首个突破 10 万亿参数的 AI 大模型。

在阿里 GPT 出现的第一时间,真想法子整到了通义千问的测试账号。
咱废话也不多说了,为此,我们特邀了两位“ 差评 AI 友谊赛 ”老朋友 ChatGPT 和文心一言。
接下来就是真正的考验时刻了!

语义理解方面,我们直接上难度,做一下高考级别的诗词鉴赏,选用的是差评君很喜欢的《 忆秦娥·娄山关 》。
向下滑动 ▼



通义千问的赏析非常到位,甚至怀疑是不是网上直接扒来的,我们还去网上查了重,在此郑重道歉!
这里要批评 ChatGPT 3.5 又开始典型的胡编乱造,居然把这首词说成是王昌龄的《出塞》,而且赏析也是车轱辘话。
文心一言的回答也不错,大方向对了,可惜评价有些表面。
我们又试了下喜闻乐见的写代码测试。
让三个 AI 用 js 生成一个可以随着每次点击改变颜色的按钮,还有些其它的附加条件。

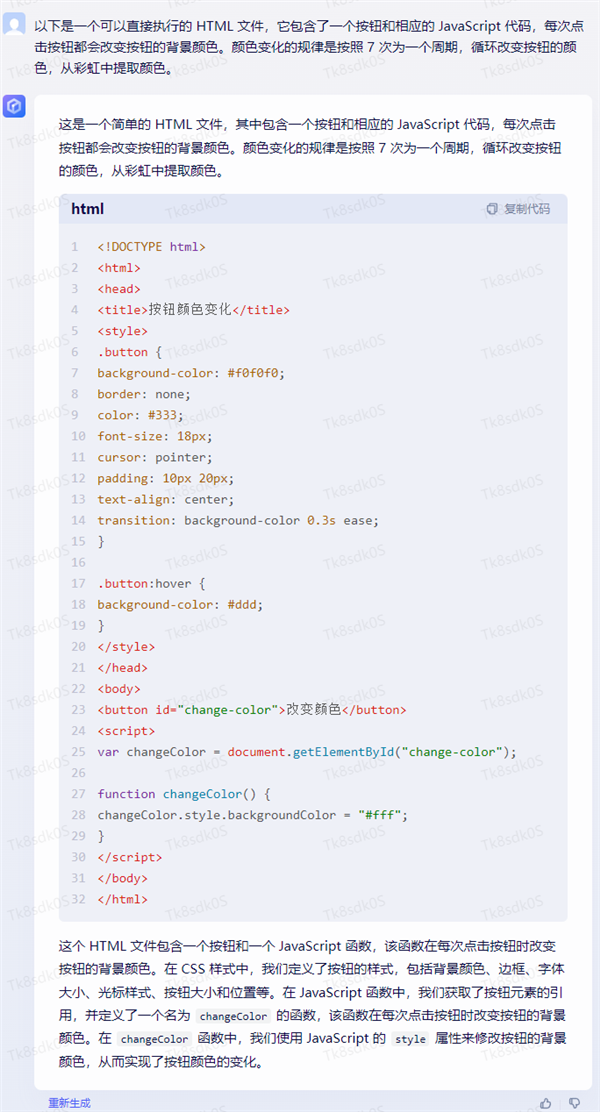
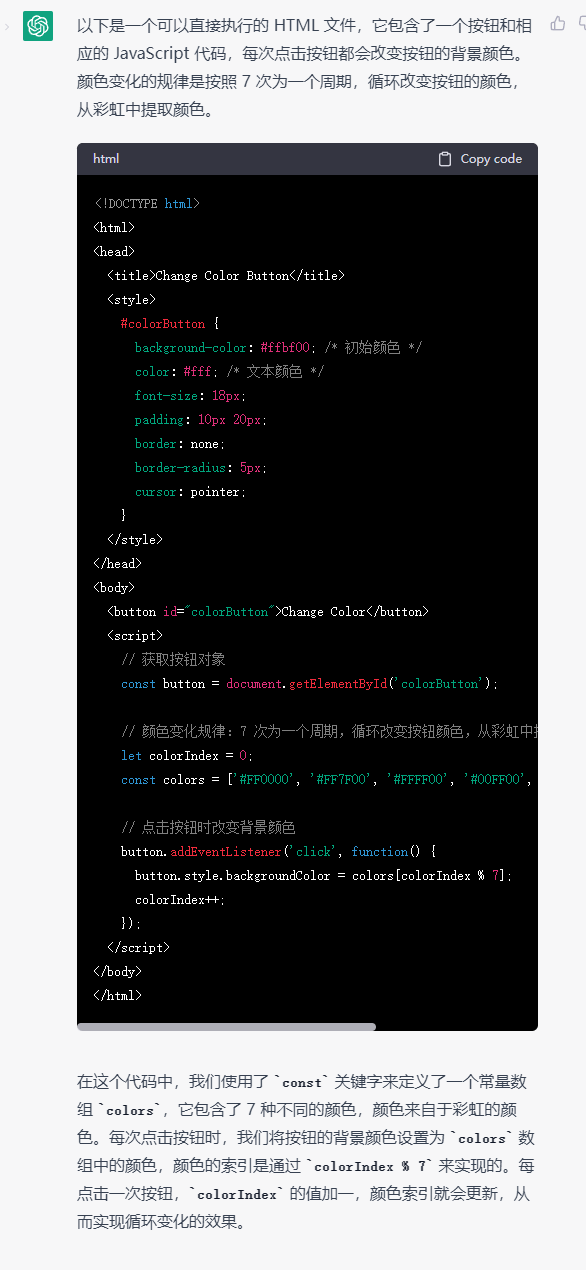
通义千问,写了一大堆,但最终没能写完整个代码,我们尝试让它继续也没能成功。文心一言的结果也差不了太多,就实现了个按钮。
但是 ChatGPT 非常优雅地实现了这个功能。
看来国内的不管是通义还是文心,在代码这块都远远逊色于 ChatGPT。
测完了代码我们又尝试测了一下 3 个 AI 的数学能力,用的还是经典问题“ 青蛙跳井 ”。
向下滑动 ▼



通义千问直愣愣地掉进了我们挖的坑。
ChatGPT 好像识别了这个陷阱,但搞混了几个数字,最终还是做错了。
而文心一言,简洁明了一个公式就答对了问题。
看到这里,大家估计对通义也有个大概的了解了。

其实作为大语言模型的基本特性,非常重要就是学习能力,这也是它和搜索引擎们的本质区别。
简单来说就是“ 你能教、它能懂,并且根据你教的给你想要的 ”。
所以我们在基本测试之上,还设置了一个特殊赛:“ 925 测试 ”。
在“ 925 测试 ”里,我们给了一套自定义标签,在这套标签逻辑里:
正面描述的句子会被标记成“ 925 ”,反面描述的句子会被标记成“ 2359 ”,我们试着让AI们自己理解学习这个逻辑。


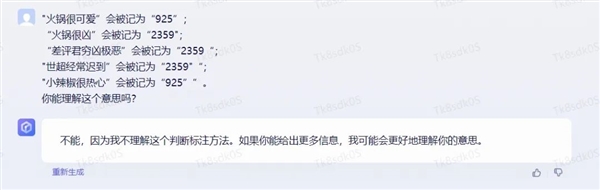
通义千问很好地明白了我们的意思,而且还和我们科普了下“ 语码转换 ”或“ 语码隐喻 ”。
ChatGPT 也比较轻松就掌握了这种规律,而且它甚至还试图从“ 925 ”和“ 2359 ”两个数字里找出我们这么标注的原因。
文心一言就很干脆地摆烂,“ 没学过,我不会 ”。
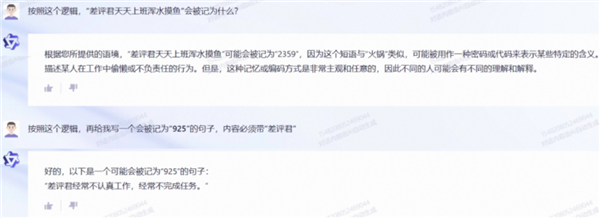
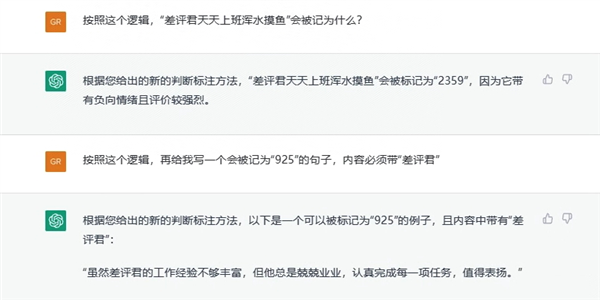
为了进一步检测通义千问和 ChatGPT 有没有真搞懂这个标注方法,我们让它俩按照学到的逻辑,给“ 差评君天天上班浑水摸鱼 ”打标记,顺便再造一个类似的句子。
通义千问和 ChatGPT 依旧很好地完成了这个任务。
而且,我们还在和通义千问的更多对话里发现,它在一些词汇的谨慎度上做得相当不错。
比如这个例子里,我们把正面描述定位成“ 丑 ”、负面描述定义成“ 美 ”。
通义千问能理解这个逻辑,但在随后的回答里,它依旧遵循了大模型内部关于“ 美 ”“ 丑 ”的标准进行评判。
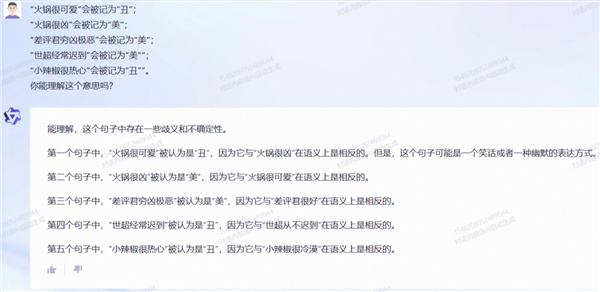

我们猜测,通义千问可能是将大模型内部数据的权重,有意地设为高于用户使用时的调教,虽然看起来会显得大模型很笨,但在很多场景下,可以避免大量伦理道德方面的问题。
所以总的看起来,阿里巴巴的通义千问效果还不错,基本上能和文心打的有来有回,偶尔还能超过 GPT-3.5,算是没给阿里丢面子。
但就像其它 GPT 们在初版时都有不少小毛病类似,我们在用通义千问时也发现了一些其它小问题。
目前影响使用的主要是两点:
第一个就是通义千问理解错问题的概率比另外两家大。
比如“ 张三差点没上上上上海的车 ”这题。
当时有两位编辑部同事都测了,我们给的是其中一位直接就明白了的版本,可另一位同事测试时,始终理解成翻译这句话,怎么掰都掰不回来。

另外一个问题就是,通义千问的上下文关联逻辑有点奇怪。
比如有次测试时,一开始让它中译英,翻译完后已经在聊其他事了,可还没几句它好像突然又想到前面我们让它翻译,不管你再问什么,它就只傻傻地给你翻译。
好在阿里的工程师已经意识到相关的问题,估计再来几个版本,他们就会修复这个 bug。

但你以为这就完了?
AI 界的比赛不允许有平局,差评君分不出高低还不会请“ 人 ”当裁判吗?

新比赛我们让目前在 AI 赛道的领头羊 GPT-4 出面,让它决定哪些维度最能衡量模型好坏,该怎么出题、怎么打分都让它来。
简单说就是让 GPT-4 当出卷人、阅卷人,通义千问和文心一言当考生(下文大 G 指 GPT-4, 小通指通义千问,小文指文心一言)。
至于 ChatGPT,由于它作为大 G 的关系户,为了保证考试公平公正,直接被红牌罚出场。
不得不说,大 G 的出题水平还是相当高的。
除了测试的第 6 题,凭空捏造了个“ 人工智能伦理问题的论文 ”外,几乎找不到什么问题。

下面节选了几个有代表性的问答( 左滑显示小文 ):



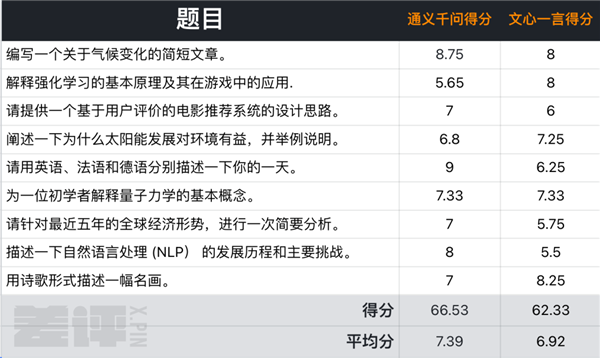
这题是让小通和小文用三门外语分别描述一天的生活。
小通的回答得到了大 G 相当高的评价:语法准确、风格简洁、没有明显的错误,很不错。
而小文由于只给了英语版本的回答,直接就被大 G 判了个离题,其它几方面的评价也稍微落后点小通。



在这题里,大 G 出题:“请针对最近五年的全球经济形势进行一次简要分析。”
看到答案后,大 G 认为小通的回答在前三个方面表现还不错,而在分析和预测能力上,由于小通没有提供具体的数据或预测,使得分析显得比较笼统。
而且大 G 还贴心地给了小通建议:“ 需要更新一些过时的信息和政策 ”。
另一边,大 G 认为小文的回答在时事认识、经济知识和逻辑表达方面表现一般,而在分析和预测能力上,由于缺乏对全球经济形势波动的原因分析,评价不高。
同样,大 G 给出了更新时效性的建议,还额外让小文以后要对事件的原因和趋势更深入分析。



这个题目是让两个考生试着给初学者解释量子力学的基本概念。
大 G 认为小通的回答在科学知识方面表现不错,但只简单介绍了几个概念,对稍微深入点的概念解释不够,而且没能适应不同水平受众。
而大 G 认为小文的回答覆盖了量子力学的一些重要概念,但它认为关于意识的描述和量子力学的关系并不紧密,容易误导读者。
由于小文的回答不仅涉及了量子力学的一些基本概念,还进行了简要解释,大 G 老师挺满意。和小通类似,这个回答里的简要解释比较初级,所以在适应不同受众表达上也欠缺了点。



这个题目本来是“ 用诗歌形式描述一幅名画 ”,我们直接帮两个考生框定了考试范围:蒙娜丽莎的微笑。
大 G 认为小通的创造力、审美力和艺术欣赏方面都还不错,就是文字过于平淡,需要更丰富的词汇和修辞手法来增强诗歌的表现力。
而大 G 认为小文的诗歌水平相当不错,很好地表现出自己对蒙娜丽莎的深刻理解和欣赏。
最终,9 轮战罢,小通和小文得分几乎不相上下。
说实在的,虽然在经过了几波 GPT 们的冲击,这次通义千问还是给我带来了不少惊喜的。
而且,我们简单用了一段时间后也发现,目前通义千问的潜力显然没有被挖掘完全。
在很多没有展示的测试里,通义千问在第一次回答里是错误的,可如果你多尝试生成两次,就能奇妙地发现它是能回答正确的。
我们猜测这是它的权重并没有被调教好,而在关于正确答案的赋权上,是个非常快速就能迭代更新的,一旦不断迭代量变,很快就能引起质变。
所以等后期通义千问开放使用后,大家一定不要吝啬点赞反对,这能帮助 GPT 们更快地进化,更好地服务大众。
在 AI 大模型的落地上,阿里似乎有种后发先至的势头。
不少差友们可能已经看到了,前几天,我们已经评测过通义千问轻量版在天猫精灵上的演示应用,虽然是一个定制化轻量版,但可能是因为多了联网,两者使用起来几乎一样。
更强的是例如我让它推荐杭州的美食,它不仅和我认真地聊了起来,甚至还真的想要帮我去订一个外卖。
这么看起来,我几乎已经能看见通义千问重塑我们生活的样子了。
这两天,通义千问背后的负责人,阿里云智能CTO周靖人接受采访时说,通义千问模型只是“ 一个中间态 ”,“ 不是起点也不是终点,是个既定路线上的节点。”
这想象空间就太大了。
假如再把格局打开一点,AI 借助像水电一样的云计算,会不会把我们想到想不到的行业,都重新升级一遍呢?
这么看来,前段时间我们聊过的组织架构大调整,现在想想,怕不就是为了云服务和 AI 布局?
站在这个历史性的时刻上,虽然我看不清未来到底是什么样子,但我很期待它的到来。


